Efficiently processing large CSV files using Laravel’s LazyCollection and PHP generators
Introduction
Have you ever faced the challenge of importing millions of records from a CSV file into your database? If you’ve tried loading everything into memory at once, you’ve probably encountered the dreaded “out of memory” error.
In this blog post, I’ll walk you through a solution that uses Laravel’s LazyCollection to import over one million rows efficiently, without exhausting your server’s memory. This project was inspired by Christoph Rumpel‘s exploration of different CSV import approaches, and I’ll show you how to implement a scalable solution that can handle files of any size.
The Problem
When dealing with large CSV files (think hundreds of thousands or millions of rows), traditional approaches often fail:
- Memory Exhaustion: Loading the entire file into memory causes PHP’s memory limit to be exceeded
- Performance Issues: Processing row by row individually is too slow
- Database Overhead: Making individual INSERT queries for each row is inefficient
- Validation Complexity: Validating millions of rows needs to be done efficiently
The Solution: LazyCollection + Batch Processing
Laravel’s LazyCollection is the perfect tool for this job. It leverages **PHP generators** to process data lazily—meaning data is only loaded when needed, not all at once. Combined with batch processing and prepared statements, we can achieve impressive performance.
Key Technologies
- Laravel 12: Modern PHP framework with excellent collection support
- PHP 8.2: Latest PHP version with improved performance
- PHP Generators: Enable lazy evaluation and memory-efficient iteration
- PDO Prepared Statements: Secure and fast batch inserts
- MariaDB 10.6: Reliable database for handling large datasets
The following rules will be considered:
1. 256MB Memory Limit
2. No Queue
How It Works
Let me break down the approach into five key steps:
1. File Reading with Generators
Instead of using only file() or fgetcsv() to load everything into memory, we use a generator function that yields one row at a time:
LazyCollection::make(function () use ($filePath) {
$handle = fopen($filePath, 'rb');
fgetcsv($handle); // Skip header
while (($line = fgetcsv($handle)) !== false) {
yield $line;
}
fclose($handle);
})
This ensures only one row is in memory at any given time, regardless of file size.
2. Data Validation
Before processing, we validate each row to ensure data quality. The validation checks:
- Customer ID: Must not be empty
- Name: Required field
- Email: Must be a valid email format
- Company: Required
- City: Required
- Country: Required
- Birthday: Required
Invalid rows are filtered out, ensuring only clean data enters the database.
3. Chunking for Batch Processing
Processing one row at a time would be too slow. Instead, we group rows into chunks of 1,000:
->filter(fn ($row) => $this->validateFields($row))
->chunk(1000)
This balance between memory usage and performance is optimal for most scenarios.
4. Batch Insert with Prepared Statements
For each chunk, we use a single prepared statement to insert all rows at once:
$stmt = $this->prepareChunkedStatement($chunk->count());
$stmt->execute($values);
The function prepareChunkedStatement() is implemented this way:
public function prepareChunkedStatement($chunkSize): PDOStatement
{
$rowPlaceholders = '(?, ?, ?, ?, ?, ?, ?, ?, ?)';
$placeholders = implode(',', array_fill(0, $chunkSize, $rowPlaceholders));
return DB::connection()->getPdo()->prepare("
INSERT INTO customers (custom_id, name, email, company, city, country, birthday, created_at, updated_at)
VALUES {$placeholders}
");
}
This dramatically reduces the number of database round trips and improves performance.
5. Performance Benchmarking
The solution includes built-in benchmarking that tracks:
- Execution Time: From milliseconds for small files to minutes for millions of rows
- Memory Usage: Shows how memory-efficient the approach is
- SQL Queries: Counts the number of database operations
- Rows Inserted: Displays the actual number of records imported
Implementation Details
Project Structure
The project is organized into clean, reusable components:
CustomersImportCommand: The main console command that orchestrates the importImportHelpertrait: Contains reusable benchmarking logic and file selection- Docker Setup: Complete containerized environment for easy deployment
Docker Architecture
The project uses a three-container setup:
- PHP 8.2-FPM Container: Handles the Laravel application
- MariaDB 10.6 Container: Database server
- Nginx Container: Web server
The setup includes automatic database migrations via an entrypoint script, so your database is always ready when containers start.
Usage Example
Running the import is straightforward:
docker exec -it laravel_app php artisan import:customers
The command presents an interactive menu to select from different CSV file sizes:
- CSV 100 Customers
- CSV 1K Customers
- CSV 10K Customers
- CSV 100K Customers
- CSV 1M Customers
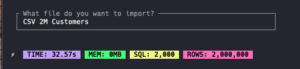
- CSV 2M Customers

After execution, you’ll see beautiful benchmark results like:
⚡ TIME: 28.5s MEM: 4.2MB SQL: 2,000 ROWS: 1,000,000
Performance Results
The real power of this approach becomes evident with large datasets:
- 100 rows: Processes in milliseconds
- 1,000 rows: Under 1 second
- 10,000 rows: A few seconds
- 100,000 rows: Under 30 seconds
- 1,000,000 rows: Under 30 seconds
- 2,000,000 rows: Under 40 seconds
The memory usage remains constant regardless of file size—typically staying under 10MB, even for millions of rows.
Key Takeaways
- LazyCollection is your friend: Use it for any large dataset processing
- Batch processing matters: Chunking reduces database overhead significantly
- Prepared statements are essential: They’re faster and more secure
- Validation early: Filter invalid data before processing saves time
- Benchmark everything: Understanding performance helps optimize further
Best Practices for Large Imports
Based on this implementation, here are some recommendations:
- Always use generators for large files—never load everything into memory
- Chunk size matters: 1,000 rows is a good default, but test with your data
- Validate before processing: It’s cheaper to filter early
- Use transactions wisely: For very large imports, consider smaller transaction blocks
- Monitor memory usage: Even with lazy loading, monitor for leaks
- Index your database: Ensure proper indexes for faster inserts
Conclusion
Importing millions of rows doesn’t have to be a nightmare. With Laravel’s LazyCollection, PHP generators, and smart batch processing, you can handle files of any size efficiently.
The solution I’ve presented demonstrates that you can:
- Process files of any size without memory issues
- Maintain excellent performance even with millions of rows
- Keep code clean and maintainable
- Track performance with built-in benchmarking
If you’re interested in exploring the code or trying it yourself, check out the GitHub repository. The project includes sample CSV files of various sizes so you can test the performance yourself.
Getting Started
To try this yourself:
- Clone the repository:
git clone https://github.com/luizfelipelopes/import-million-rows-with-validations.git cd import-million-rows-with-validations - Build and start:
make build - Run the import:
docker exec -it laravel_app php artisan import:customers
The project is fully containerized, so you’ll have everything running in minutes. Give it a try and see how efficiently you can import large datasets!
Have questions or want to share your own approach? Feel free to reach out or contribute to the project!

